开局
“ 开局一张图,内容全靠编 ”
先从需求说起:现在需要将shodan上关于工控相关协议和产品设备的指纹数据下载下来,录入本地的数据库
好在shodan提供了data下载的功能,不过下载一次消耗1 export credit = 10,000 results,而这个credit是需要购买的。
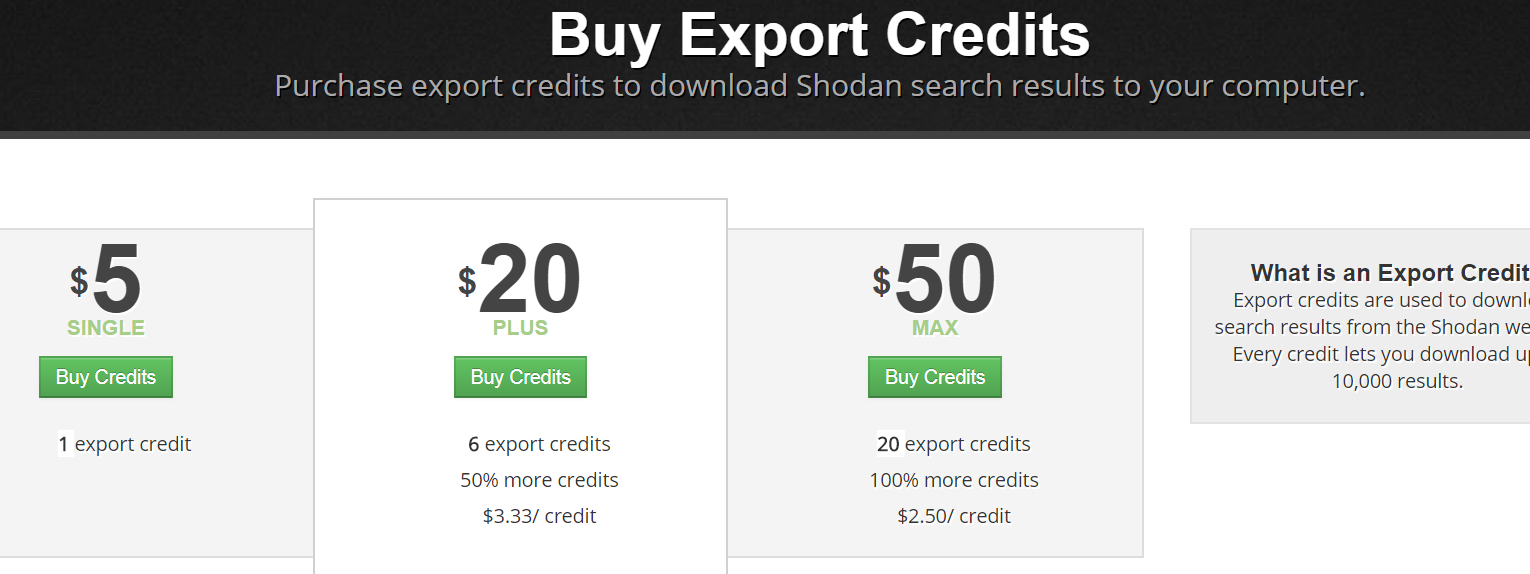
通过一些途径,我们的账户现在有了一些credit可供下载数据,而shodan也提供三种下载数据的文件格式(json、csv、xml)
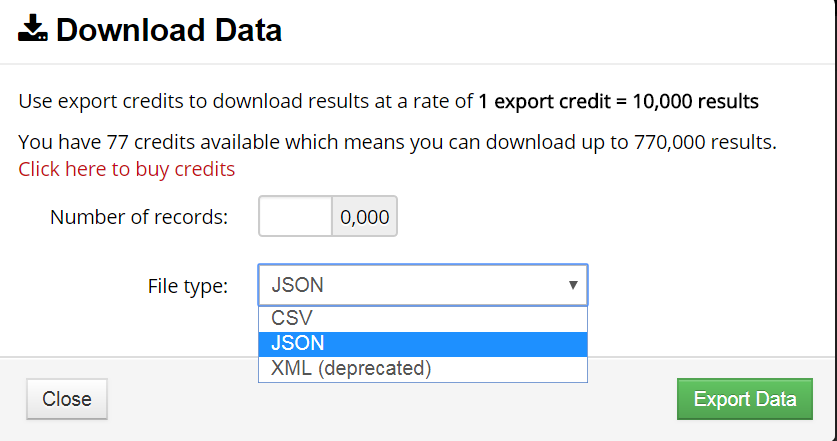
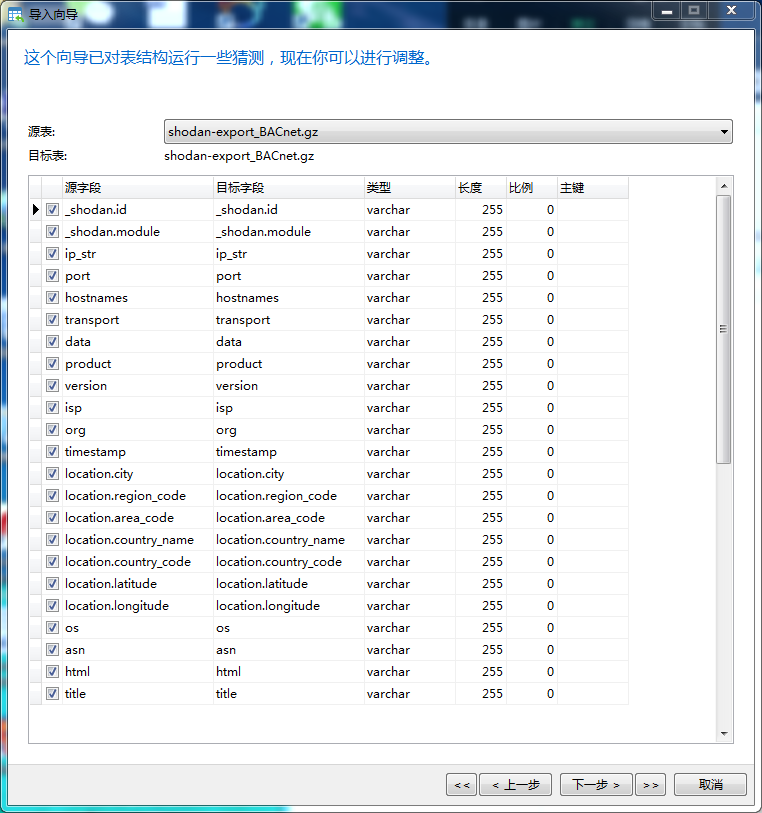
按说,这三种格式的文件是可以直接通过Navicat导入到数据库的
困境
但是,我们从shodan上下载的文件准备直接导入数据库时候发生了一些问题:
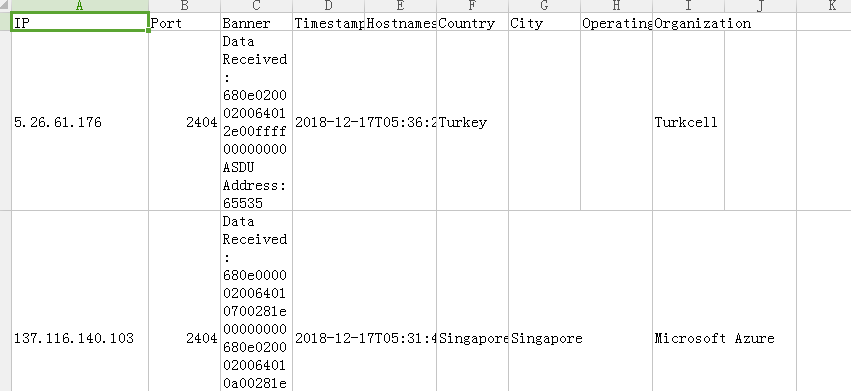
- shodan下载出的csv文件所存储的信息有效,缺少服务、产品型号、经纬度等
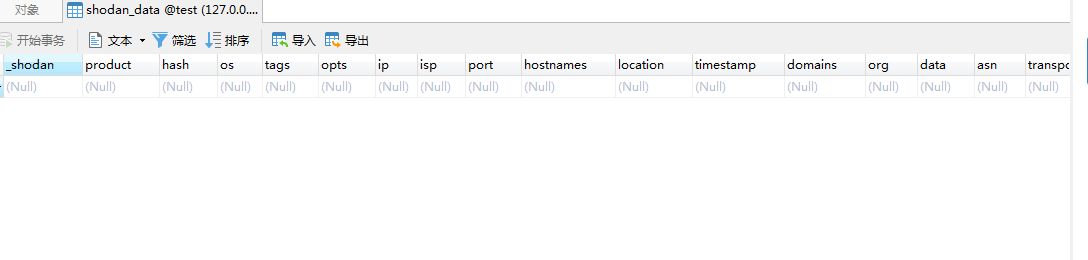
- 直接用下载出的json文件去导入数据库,发现只能导入字段名,而没有值
为了解决这个困惑,查阅相关资料,我们了解到shodan有python版的库,其中包含了格式化的命令功能
pip install shodan
shodan
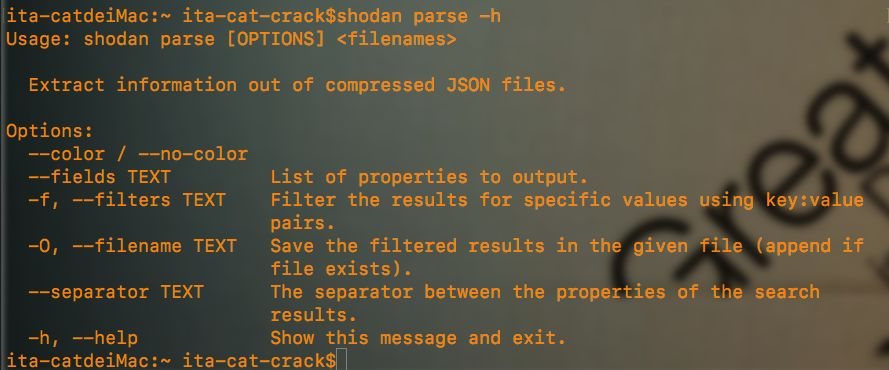
可以通过以下命令来对json文件进行格式化操作,输出包含特定值的csv格式文件
shodan parse --fields ip_str,hostnames,isp,org,timestamp --separator , xxx.json >> xx.csv
然而,结果还没达到我们想要的结果,如下图是一个标准的shodan给的json数据格式
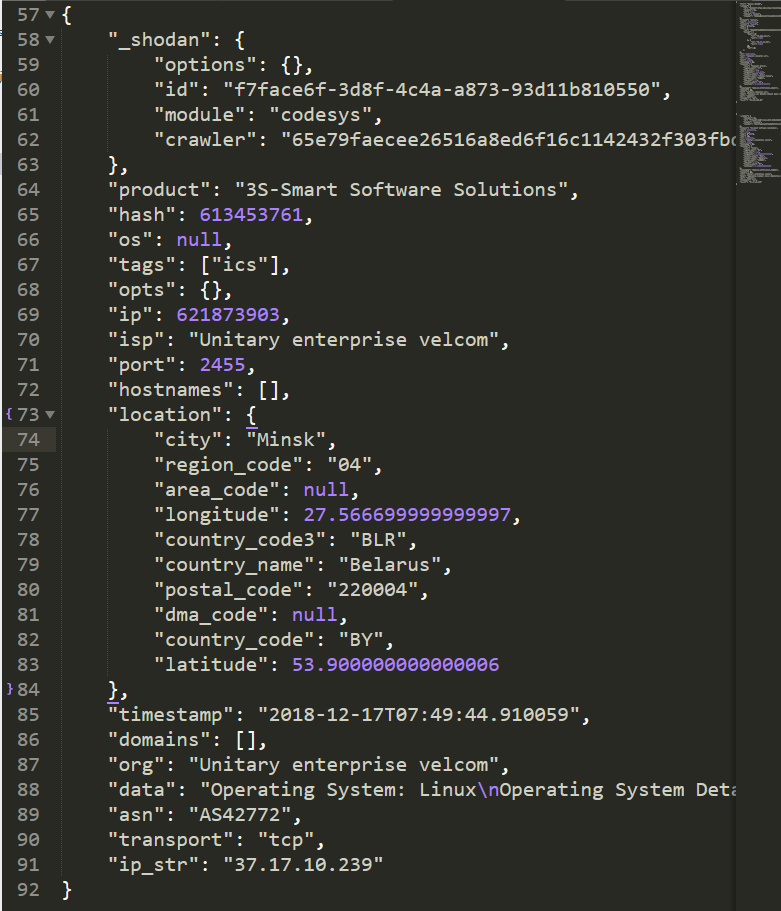
我们执行shodan parse命令只能格式化出跟节点的数据,如ip|isp|port|hostnames|timestamp等,而对第二节点的数据却难以获取到,如location节点下的city|region_code|area_code等
那如果我们直接取location节点下的所有数据呢?输出的结果如下图
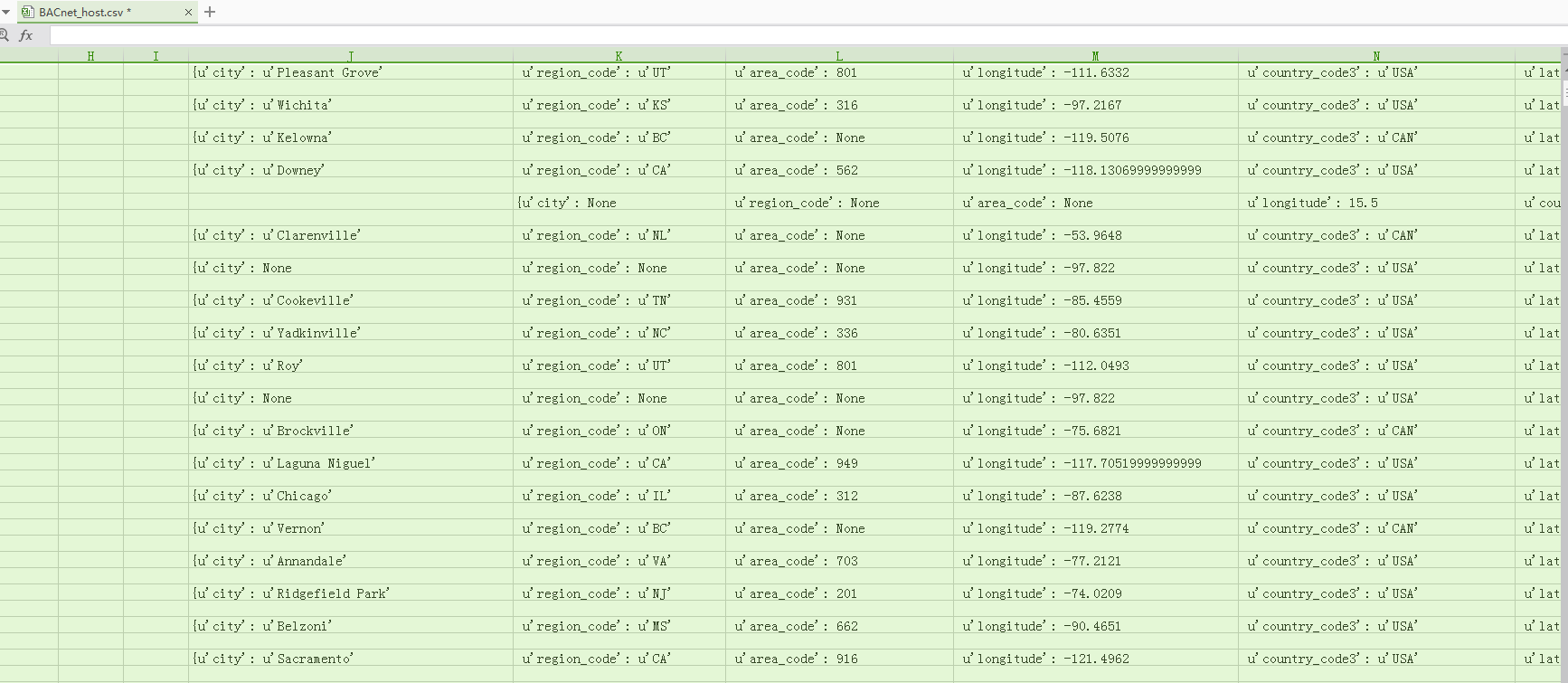
可以看到,虽然这样是把location节点下所有的数据都取出来了,但是却有一些冗余数据,不符合要求,还得需要二次处理这些数据才能入库
那还有其他可以直接取出格式化的数据、不需要二次处理、直接导入数据库的方法吗?
柳暗花明
这里我们再次研究发现shodan还有个内置命令
shodan convert
convert命令可以把Shodan生成的JSON报告转化成KML和CSV格式
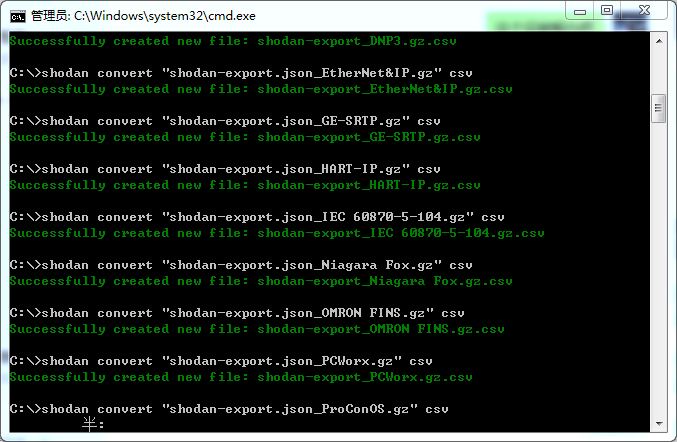
输出的csv内容如下
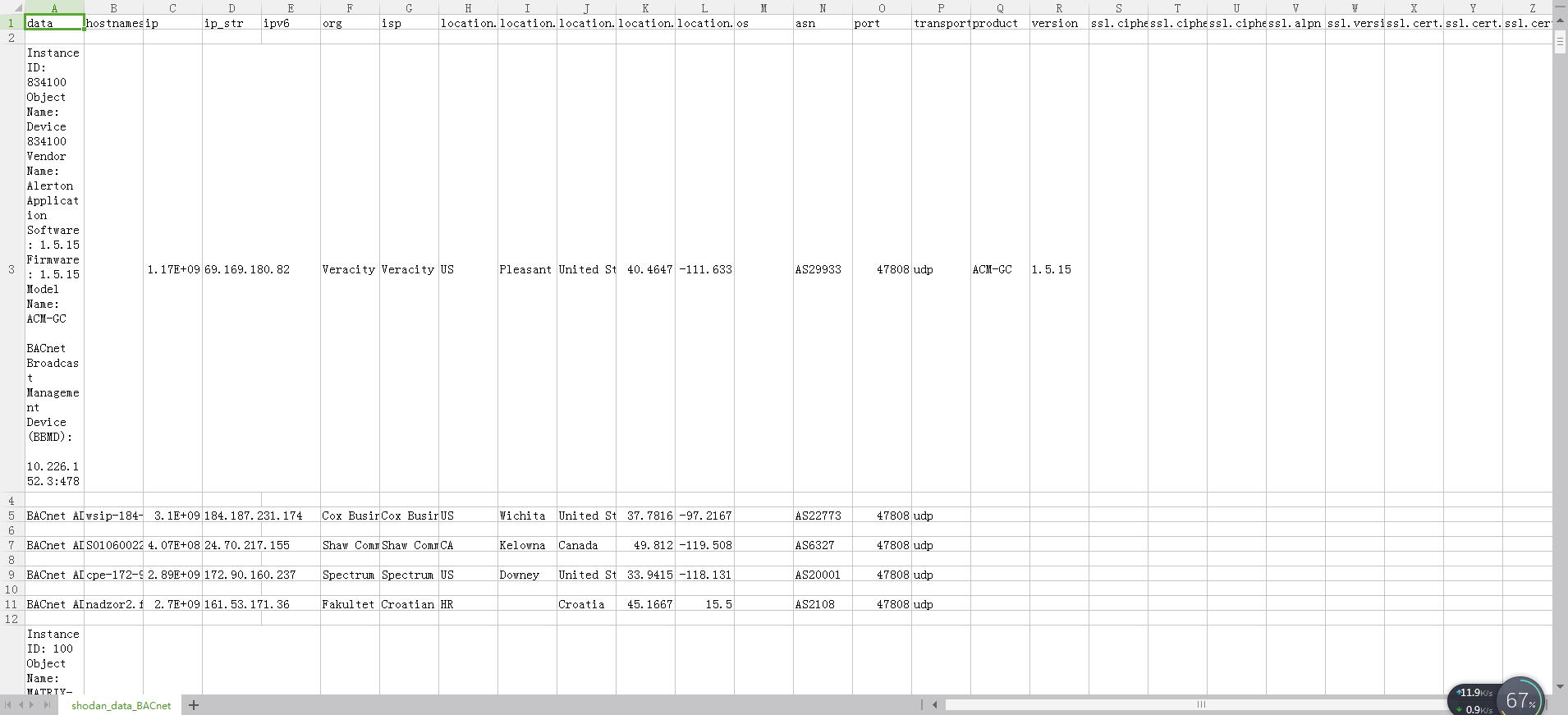
确实比上一次的数据要整洁的多了,但多了一些不需要的字段,得想想办法去除,要是能自定义输出的字段数据就好了
于是,我们想到可以研究下shodan的python库源码,看看能不能修改点代码什么的
找到shodan的python安装包,寻找跟convert有关的功能模块代码
shodan-1.10.4.tar\shodan-1.10.4\shodan\cli\converter
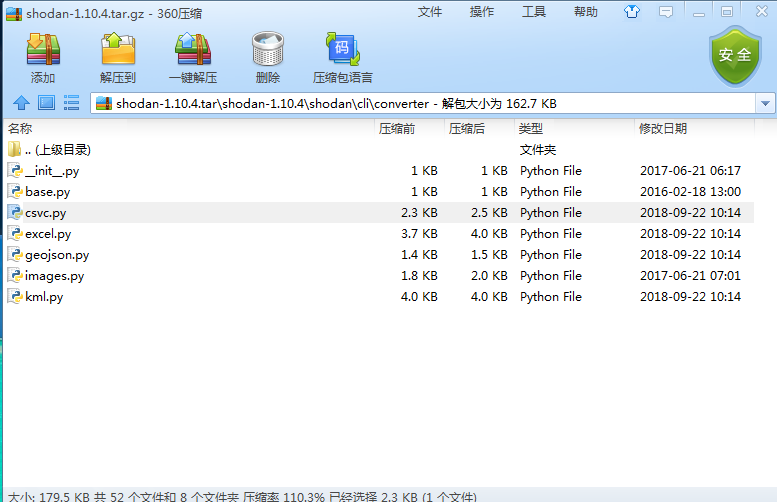
看来我们要想修改的代码可能就是csvc.py
我们按原代码的格式修改需要提取的字段值
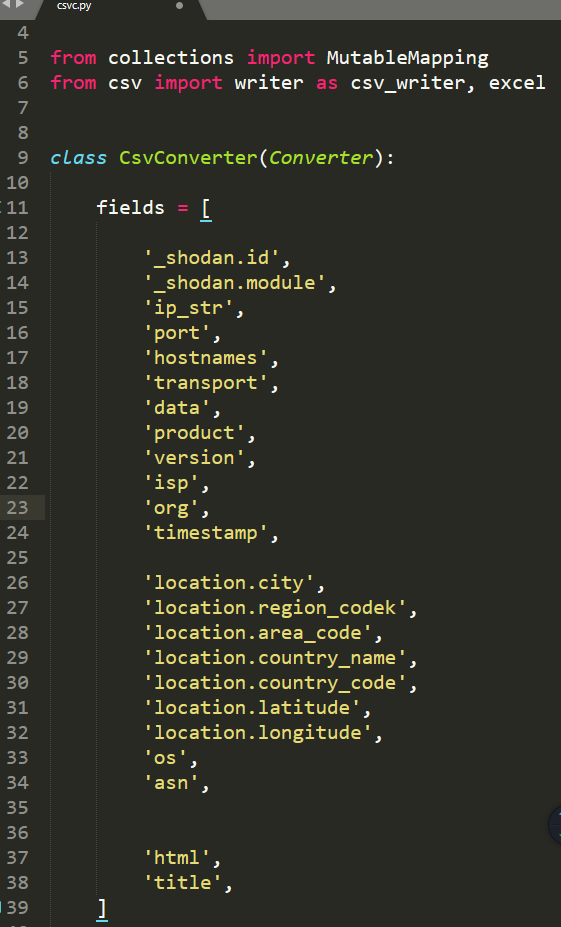
保存之后,再重新安装shodan
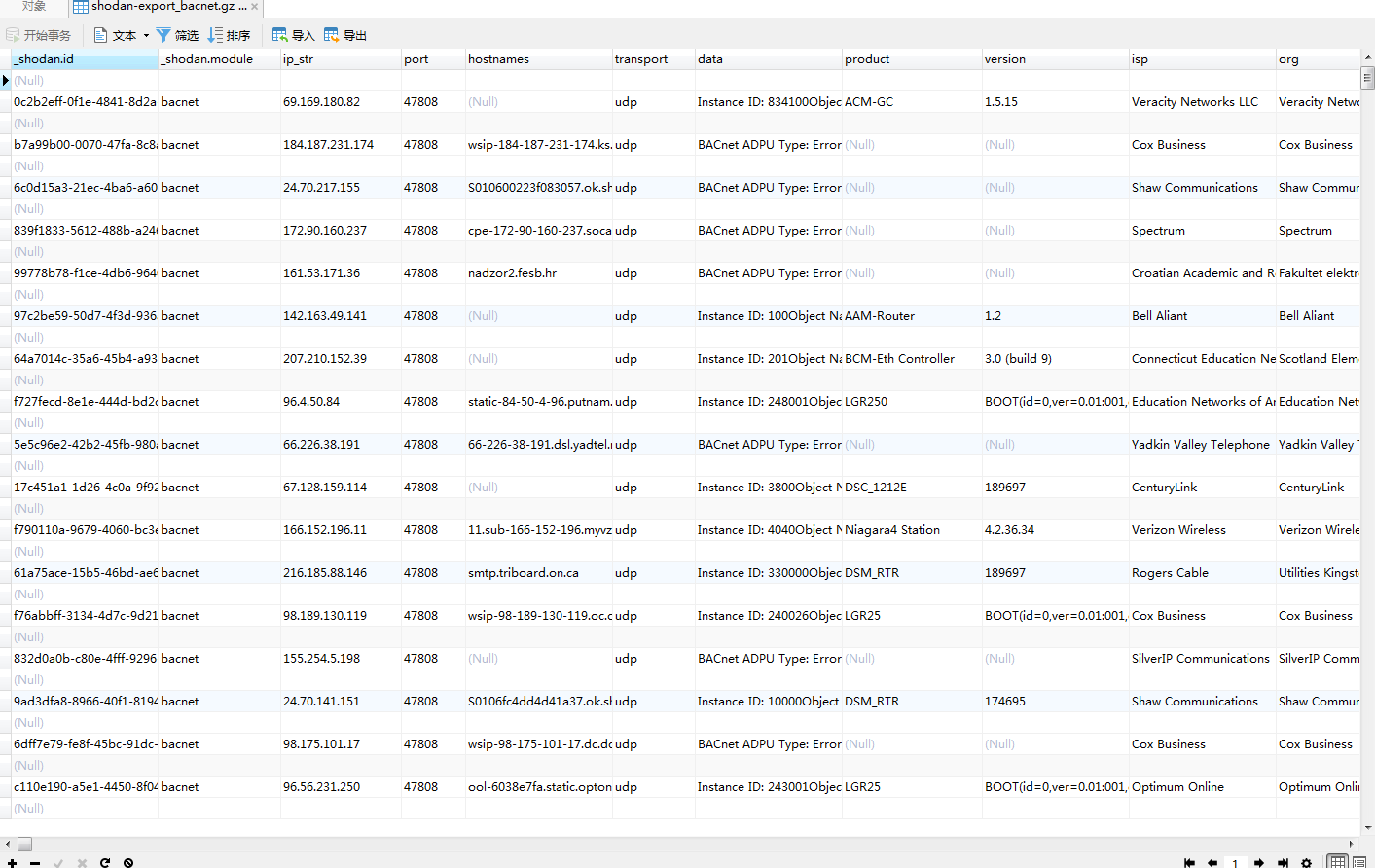
此时输出的结果就已经达到我们想要的了
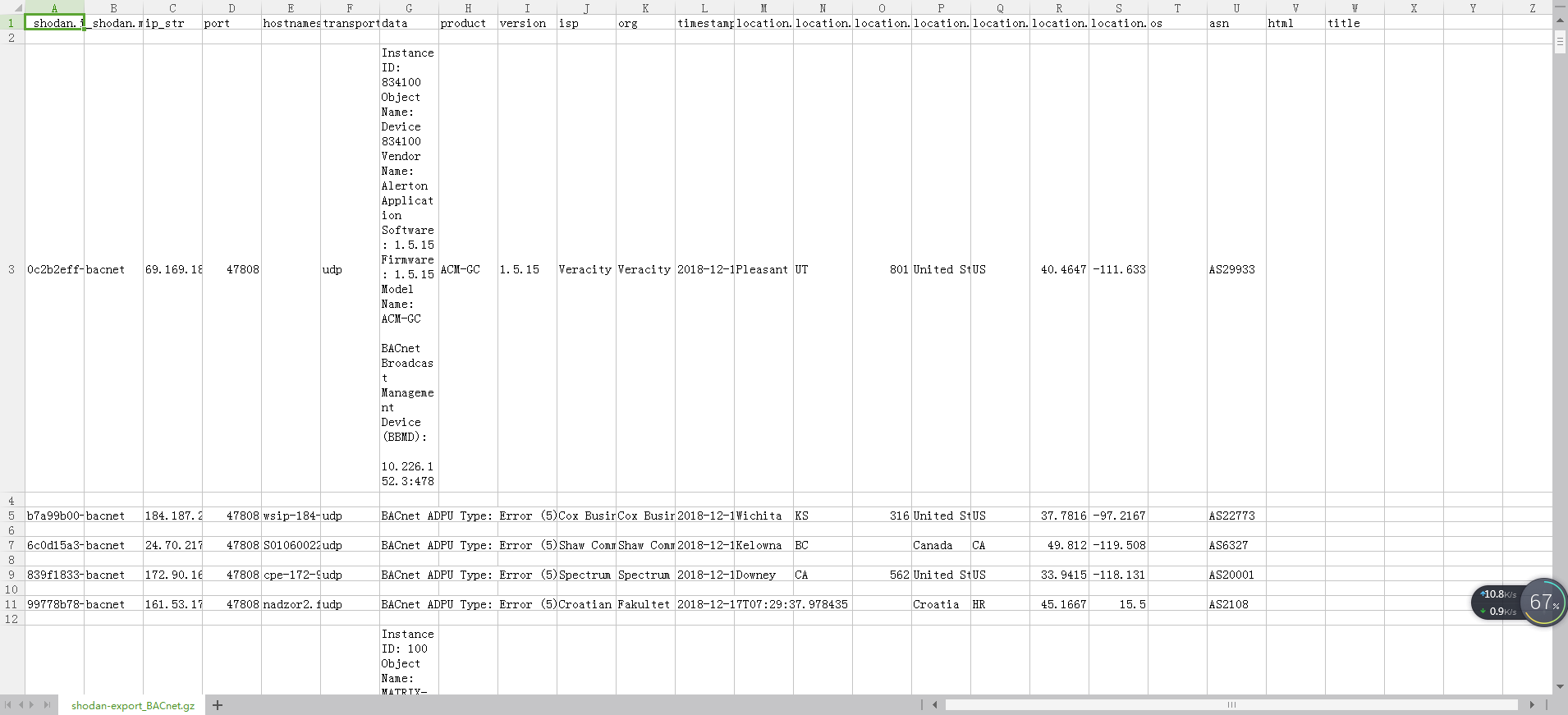
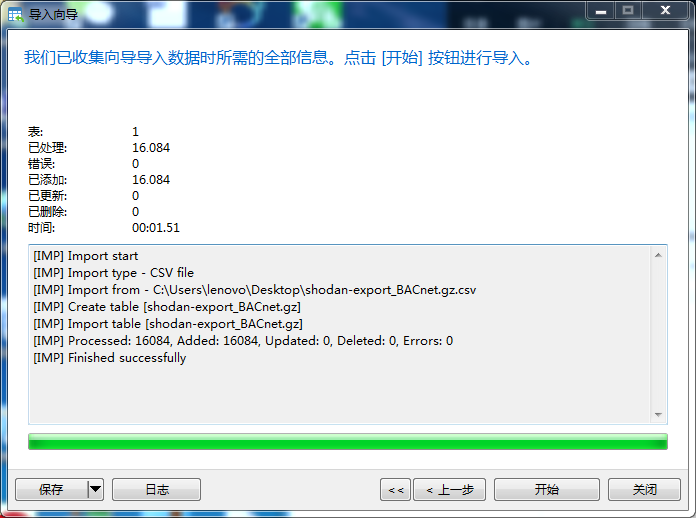
现在,我们再用Navicat导入数据库就会非常顺利了